Astazi imi propun ca obiective:
- Va invit sa cititi TOATE postarile LFA si Compilatoare de pina azi. Ceea ce presupun ca ati facut deja.
- Sa terminati compilatorul din cartea despre constructia compilatoarelor,conform capitolului 7 [aprox pg 63,depinde de editie, editia verde are numarul paginii cu 2 unitati mai mic, deci de la pagina 61]
GENERAREA CODULUI
Dragii mei, de fapt in acest capitol programam ceea ce face, productiv, cu adevarat, compilatorul. Genereaza cod. Sper ca v-ati familiarizat cu limbajul de asamblare al masinii virtuale, in caz contrar revedeti precedentele laboratoare de compilatoare din saptamana S12.
Deschideti manualele la pg dintai a Cap 7 ! Ceea ce aveti in manual este traducerea notelor profesorului Anthony, dar vreu sa fac niste comentarii, explicative. Cititi primul paragraf:
Ne spune ca de la textul sursa se trece la o forma intermediara, care poate fi:
- arbore explicit (nu e cazul la comp. nostru)
- arbore implicit (cand lucrezi cu o stiva...)
- cvadruple (nu este cazul)
- un limbaj de asamblare (nu este cazul)
Practic: Noi vom defini un mod de a transcrie in cod fiecare instructiune din Simple, imediat ce parserul recunoaste , chiar si parti, din ea, astfel incat la finalul recunoasterii ei, codul ei sa fie complet generat. Va trebui sa explicam cum arata codul generat pentru fiecare fel de instructiune sau declaratie.
Cititi pg 1 a Cap 7, partea de jos; o comentez:
Programul compilat lucreaza cu un segment de date, un segment de cod si o stiva. Se insista aici deoarece vor exista in compilator niste subrutine:
+ una care adauga cod in segmentul de cod
+ una care mai aloca spatiu pentru date, variabile, pe stiva
- una care va aloca spatiu pentru date pe heap (zona de date) similara, dar noi nu vom folosi asa ceva fiindca Simple nu are o instructiune new pentru alocare pe acest heap.
TRADUCEREA FIECARUI FEL DE INSTRUCTIUNE
Dati pagina la [pg 64/pg 62 - aII-a pg]. Cititi paragraful 1 de sus.
Traducerea declaratiilor:
integer x,y,z ---> DATA 2 (nu DATA 3)
Traducerea atribuirii:
x:= expresie va genera urmatorul cod:
-----------------
| cod pt | Acest cod se genereaza prin parcurgerea expresiei
| calculul | si va pune valoarea expresiei in stiva, la executie.
| expresiei |
-----------------
| STORE @X| Store @X va scoate valoarea din stiva si o va pune la adresa
----------------- variabilei X.
Nota: daca va uitati in codul generat din anexa, argumentul lui STORE este chiar adresa, nu numele variabilei.
Traducerea if ... then ... else ... fi-ului.
Genereaza:
---------------------
| cod pt | Acest cod se genereaza prin parcurgerea expresiei
| calculul | si va pune valoarea expresiei in stiva, la executie.
| conditiei |
---------------------
| JMP_False L1 | Daca este fals in stiva sar la etichetea L1:
---------------------
| codul | Acest cod se genereaza prin parcurgerea ramurii then
| intructiunilor|
| de dupa then |
---------------------
| GOTO L2 | A, terminat ramura then sar la final, dupa if.
----------------------
L1: Cod pentru |
| ramura else | Acest cod se genereaza prin parcurgerea ramurii else.
----------------------
L2: Aici incepe urmatoarea instructiune de dupa if.
Atentie la L1 si L2: Aceste etichete, aceste adrese, nu se cunosc in momentul cand compilarea ajunge la JMP_false L1 respectiv la GOTO L2.
Corectati greselile de pe manual ! Nu BR l2 ci GOTO L2 nu end ci fi. Dati pagina !
Ne ocupam acum de instructiunea while...
Asa arata codul instructiunii while:
---------------------
L1: cod pt | Acest cod se genereaza prin parcurgerea conditiei
| calculul | si va pune valoarea expresiei in stiva, la executie.
| conditiei |
---------------------
| JMP_False L2 | Daca este fals in stiva sar la etichetea L2, termin bucla !
---------------------
| codul | Acest cod se genereaza prin parcurgerea
| intructiunilor| corpului buclei while.
| din bucla |
---------------------
| GOTO L1 | A, terminat bucla then sar la inceput sa o reiau!
----------------------
L2:
Ne ocupam acum de instructiunea read...
Codul este foarte simplu:
read X se va compila intr-o simpla instructiune:
---------------------------
| READ_INT @X | Instr. READ a masini virtuale si adresa lui X (in seg.)
-------------------------- ca parametru.
Nota: la masina noastra virtuala adresa lui X este de fapt indice in segmentul de stiva.
Instructiunea citeste de la consola si pune in stiva.
Dati pg inapoi si uitati-va cum executa masina virtuala pe read. [pg 58-59]
Ne ocupam acum de instructiunea write...
Codul este foarte simplu:
write expresie se va compila intr-un cod format din codul expresiei + o simpla instructiune:
---------------------
| cod pt | Acest cod se genereaza prin parcurgerea expresiei
| calculul | si va pune valoarea expresiei in stiva, la executie.
| expresiei |
----------------------
| WRITE_INT | Instr. WRITE a masini virtuale va scoate din stiva si
---------------------- va tipari rezultatul.
Nota: la masina noastra virtuala adresa lui X este de fapt indice in segmentul de stiva.
Instructiunea citeste de la consola si pune in stiva.
Dati pg inapoi si uitati-va cum executa masina virtuala pe write. [pg 58-59]
Exercitiu:
Fie instructiunea:
Write 2*3+4
Scrieti codul generat si explicati prin desene succesive cum evolueaza stiva !
Daca nu reusiti sa faceti exercitiul, inseamna ca nu intuiti cum se face traducerea expresiei, pe baza formei sale poloneze postfixate. Sa trecem la:
Traducerea expresiilor
Sa citim impreuna paragraful de la pg 63/sau 64 de jos.
In esenta regulile sunt simple, iar daca parserul isi face treaba si parcurge corect sintaxa expresiei, urmarind corect prioritatea operatorilor, treaba merge:
constanta se compileaza in :
LD_INT constanta /* parametrul instr LD_INT e valoarea constantei */
variabila se compileaza in:
LD_VAR @variabila /* parametrul este nr-pozitie al variabilei in
segmentul de stiva */
Expresia de forma: e1 op e2
cod pentru e1
cod pentru e2
instructiunea care corespunde operatiei aritmetice.
Sa reluam putin exercitiul, exemplul de mai sus:
Write 2*3+4:
2 * 3 + 4 in forma poloneza postfixata este:
2 3 * 4 + (asezati operanzii in ordine si operatorii printre ei ca sa faca calculele corect, intr-o stiva). Iar cand transcriem in limbaj masina:
LD_INT 2
LD_INT 3
MULT
LD_INT 4
ADD (Intrebare, era ADD sau era PLUS, de unde aflati ?)
Si se mai adauga un :
WRITE_INT
Codul final generat de instructiunea write 2*3+4 va fi deci:
LD_INT 2
LD_INT 3
MULT
LD_INT 4
ADD
WRITE_INT
MODULUL GENERATOR DE COD CG.h
Sa citim intai explicatiile de la pg 64/66, pina la modificari ale modulului ST.h. Ce ati inteles ?
Intrebari/Intrebare de control:
Gasiti in modulul CG.h portiunile de cod:
a) Functia care returneza adresa curenta, c-a s-o memoram pt o eventuala completare mai tarzie de cod si eticheta ?
R: gen_label()
b) Functia care returneza adresa curenta in care se va genera cod, incrementand-o ?
R: data_location()
c) Functia care genereaza cod la adresa curenta ?
R: gen_code()
d) Functia care peticeste cod, adica genereaza cod la o adresa data ?
R: back_patch()
e) Contorul in segmentul de cod, care avanseaza cand generam codul ?
R:code_offset
f) Contorul in segmentul de stiva, care avanseaza cand adaugam variabile ?
R: data_offset
Daca nu ati gasit raspunsurile, descifrati va rog codul din CG.h.
Scrieti in proiectul dvs fisierul CG.h cu tot aceste continut.
Nu uitati sa includeti fisierul in Simple.y, portiunea cu includeri.
MODIFICARI ALE MODULULUI ST.h
Dati la pg acestui subcapitol 65/68 depinde de editie.
Explicam de ce, ***** este nevoie de asa ceva ?
Daca va mai amintiti, e mult de atunci, micul nostru modul - tabela de simboluri colectiona simbolurile (aka, numele variabilelor) de la analiza lexicala, (de la codul generat de LEX/FLEX) si le punea intr-o lista.
Dar lista nu avea decat:
- pointer next la urmatorul element
- numele variabilei
Dar la generarea de cod, codul unei expresii cu variabile ar trebui sa arate cam asa:
Codul final generat de instructiunea write X*Y+Z va fi deci:
LD_VAR @X <- @X va fi inlocuit cu adresa-indice a lui X pe stiva
LD_VAR @Y <- la fel, samd
MULT
LD_VAR @Z
ADD
WRITE_INT
Daca variabilele X,Y,Z ar fi in pozitiile: 0,1,2 , adresele lor ar fi 0,1,2,3, iar codul va arata asa, de fapt:
LD_VAR 0
LD_VAR 1
MULT
LD_VAR 2
ADD
WRITE_INT
Dar pentru a genera asa un cod, trebuie ca in lista = in tabela de simboluri, pentru fiecare variabila, sa existe adresa ei ! Ceea ce nu exista !
Structura elementului de lista era asa: [cam pe la pg 34 aparea...]
struct symrec
{
char *name; /* numele simbolului - identificatorul variabilei */
struct symrec *next; /* legatura cu urmatorul din lista */
};
Noua ne trebuie insa asa ceva, in care sa am si adresa variabilei!
struct symrec //NOUL SYMREC
{
char *name; /* numele simbolului - identificatorul variabilei */
int offset; /* adresa-indice a variabile in segmentul de date */ struct symrec *next; /* legatura cu urmatorul din lista */
};
Dar cine sa o puna acolo ? Pai cine pune a variabila acolo ? Functia putsym() !
Putsym arata asa:
symrec * putsym (char *sym_name)
{
symrec *ptr;
ptr = (symrec *) malloc (sizeof(symrec));
ptr->name = (char *) malloc (strlen(sym_name)+1);
strcpy (ptr->name,sym_name);
ptr->next = (struct symrec *)sym_table;
sym_table = ptr;
return ptr;
}
Acum arata asa, si foloseste noul symrec de mai sus:
symrec * putsym (char *sym_name)
{
symrec *ptr;
ptr = (symrec *) malloc (sizeof(symrec));
ptr->name = (char *) malloc (strlen(sym_name)+1);
strcpy (ptr->name,sym_name);
ptr->offset = data_location(); /* completarea campului offset */
ptr->next = (struct symrec *)sym_table;
sym_table = ptr;
return ptr;
}
Puteti explica ce am adaugat ?
Raspuns: La fiecare apelare a lui putsym, care pune o variabila noua in tabela de simboluri,se incrementeaza prin intermediul apelului data_location() contorul de variabile in segmentul de stiva (va indica o locatie noua)si se memoreaza valoarea lui neincrementata - ultima pozitie ocupata, ca fiind adresa variabilei.
Raspuns scurt: La fiecare apelare a lui putsym, imping pointerul mai departe si in spatiul de sub el va fi variabila aceasta noua a carei adresa se memoreaza in tabela.
In acest moment, salvati noua forma a modului ST.h in dosarul proiectului.
DEABIA ACUM TRANSFORMAM PARSERUL IN COMPILATOR
Modificarile parserului:Simple.y
Dati pagina aici, la [pg 66/68]
Sa citim impreuna pg 66..67...68
Ca totul =? sa ne functioneze este nevoie intai de niste pregatiri.
Cu siguranta niste chestii lipsesc, nefiind implementate nicaieri:
a) Noul fisier CG.h nu este inclus in Simple.y , oricum verificati sa fie !
b) Instructiunile if si while au nevoie de doua etichete, L1 si L2 si o structura de date care sa contina cele doua etichete ar fi utila ! ( Ar fi bune chiar doua, dar sunt atat de similare ca ne multumim cu una singura !). Structura asta va fi un fel de parte (de valoare semantica) asociata i-urilor si write-urilor.
c) Un alocator, o functie care sa aloce noua structura.
d) Ceva care sa extraga adresele variabilelor (element noi) si sa le puna in cod.
Cautarea variabilei o face context_check() dar ea nu face generare de cod.
De aici ideea simpla de a pune gen_code() in context_check().
Noua functie context_check() , cu mai multi parametri devine o functie generatoare de instructiuni de cod care folosesc variabile.
e) Constantei i se asociaza (ca semantica) un numar, Variabilei i se asociaza un string , in plus, NOU, if-ului si while-ului li se mai asociaza si acea pereche de adrese. Deci acel union, record-ul semantic, se va modifica.
Si bineinteles, apare un %token <lbls> care corespunde campului adaugat lbls.
Nota: Acesti %token cu < > nu sunt atomi lexicali in sensul de la teoria gramaticilor.
Abia acum puteti citi inceputul fisierului Simple.y, varianta modificata:
Veti gasi in el:
a) Noul fisier CG.h nu este inclus in Simple.y , oricum verificati sa fie !
#include "CG.h" /* Generator de cod */
b) Instructiunile if si while au nevoie de doua etichete, L1 si L2 si o structura de date care sa contina cele doua etichete ar fi utila ! ( Ar fi bune chiar doua, dar sunt atat de similare ca ne multumim cu una singura !). Structura asta va fi un fel de parte (de valoare semantica) asociata i-urilor si write-urilor.
struct lbs /* Pentru etichetele de la if si while */
{
int for_goto;
int for_jmp_false;
}; /* Punct si virgula – Obligatoriu ! */
c) Un alocator, o functie care sa aloce noua structura.
struct lbs * newlblrec() /* Alloca spatiu pentru etichete */
{
return (struct lbs *) malloc(sizeof(struct lbs));
}
d) Ceva care sa extraga adresele variabilelor (element noi) si sa le puna in cod.
Cautarea variabilei o face context_check() dar ea nu face generare de cod.
De aici ideea simpla de a pune gen_code() in context_check().
Noua functie context_check() , cu mai multi parametri devine o functie generatoare de instructiuni de cod care folosesc variabile.
context_check( enum code_ops operation, char *sym_name )
{symrec *identifier;
identifier = getsym( sym_name );
if ( identifier == 0 )
{ errors++;
printf( "%s", sym_name );
printf( "%s\n", " is an undeclared identifier" );
}
else gen_code( operation, identifier->offset );
}
e) Constantei i se asociaza (ca semantica) un numar, Variabilei i se asociaza un string , in plus, NOU, if-ului si while-ului li se mai asociaza si acea pereche de adrese. Deci acel union, record-ul semantic, se va modifica.
Si bineinteles, apare un %token <lbls> care corespunde campului adaugat lbls.
Nota: Acesti %token cu < > nu sunt atomi lexicali in sensul de la teoria gramaticilor.
%}
%union /* semrec - Record-ul semantic */
{
int intval; /* Valoarea constantei intregi */
char *id; /* Identificatorul */
struct lbs *lbls /* Adrese etichetate pentru backpatching*/
}
Verificati si felul cum arata functia install():
install ( char *sym_name )
{
symrec *s;
s = getsym (sym_name);
if (s == 0)
s = putsym (sym_name);
else { errors++;
printf( "%s is already defined\n", sym_name );
}
}
ACUM PUTETI CORECTA MODULUL Simple.y de la inceput pina la partea cu regulile gramaticale, acolo unde incepea gramatica limbajului:
%%
program: LET si asa mai departe.
DEABIA DE AICI INCEPE PROPRIUZIS GENERATORUL DE COD
Dati pagina la pagina 70/72 acolo unde scrie:
/* Declaratiile pentru C si Parser */
Acesta pagina cuprinde generatorul de cod al compilatorului:
Sa o explicam putin, desi de acum ar trebui sa INTELEGETI deja cum functioneaza acesta si sa REGASITI, scrisa in C, in acele acolade, toate regulile generarii de cod de mai sus.
Ideea principala este ca in analiza sintactica, printre etapele recunoasterii diferitelor "bucati" de instructiune, se insereaza acele acolade cu cod {...}
care spun generatorului ce si cit cod sa genereze in acel moment sau ce altceva sa faca, de exemplu sa aloce loc pt L1 si L2 sau sa faca backpatching-peticire de cod la o adresa anterioara.
De exemplu:
program :
LET
declarations
IN { gen_code( DATA, data_location()-1 ); }
commands
END { gen_code( HALT, 0 ); YYACCEPT;}
;
Cum cititi si intelegeti asa ceva:
Iata cum compilez un program :
il citesc pe LET
compilez declarations
il citesc pe IN si generez instructiunea DATA, data_location()-1
compilez commands
il citesc pe END si generez instructiunea HALT, 0
execut YYACCEPT ca sa opresc progr gen. de Bison.
Veti STUDIA cu atentie ceea ce urmeaza si veti gasi scris in C, in acoladele care "impaneaza" regulile sintactice, tot generatorul de cod expus si explicat mai inainte. Desenati structurile de date, listele, si codul generat.
Aveti o ora pentru aceasta, timp in care trebuie sa actualizati si fisierul Simple.y.
Ok, ora a trecut va rog sa trimiteti intrebari pe e-mail despre generatorul de cod !
Trecem la paragraful urmator:
Modificari ale analizorului lexical
Dati pagina la pg 71/73, functie de editie.
Trebuie sa ne asiguram ca fisierul cu descrierea analizorului lexical contine cod care sa spuna ca se transmit informatiile (semantice) despre constante si variabile.
Cateva explicatii sunt necesare aici:
a) La numere, stringul yytext (variabila yacc care contine chiar atomul lexical) trebuie transformat in numar, seocupa functia atoi() de asta.
Detalii: https://www.tutorialspoint.com/c_standard_library/c_function_atoi.htm
b) La identificatori, trebuie facuta o copie a stringului din bufferul de intrare. Prin constructia analizorului lexical, variabila yytext isi va tot schimba valoarea. Ceea ce facem cu strdup().
%{
#include <string.h> /* for strdup */
#include "simple.tab.h" /* for token definitions and yylval */
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ { yylval.intva l = atoi( yytext );
return(NUMBER); }
...
... aici sunt celelalte definitii
...
{ID} { yylval.id = (char *) strdup(yytext);
return(IDENTIFIER); }
[ \t\n]+ /* consuma spatiu tab si enter */
. { return(yytext[0]);}
%%
Salvati actualizarile , salvati noua versiune a lui Simple.lex.
PRINTAREA CODULUI GENERAT
Adaugati, deoarece acum o puteti apela din main()-ul compilatorului, functia:
void print_code()
{
int i = 0;
while (i < code_offset) {
printf("%3d: %-10s%4d\n",i,op_name[(int) code[i].op], code[i].arg ); i++; }
}
Nota: Nu mai este nevoie de formatul ld (long decimal, numere zecimale lungi) daca ati trecut la 64 de biti.
Acum puteti reconstrui compilatorul.
Comenzile sunt in Anexa A2.
> bison -d Simple.y
sau
> bison -dv Simple.y
Simple.y contains 39 shift/reduce conflicts.
> gcc -c Simple.tab.c
> flex Simple.lex
> gcc -c lex.yy.c
> gcc -o Simple.exe Simple.tab.o lex.yy.o -lm -lfl
> Simple.exe test_simple
Ignorati cu seninantate Warning-urile sau daca doriti sa scapati de ele, faceti in cod modificarile indicate: de exemplu main va trebui sa returneze int, la fel si alte functii, inclusiv context_check(), ele se bazau pe o regula implicita de la un anumit dialect de C inteles de gcc.
In final compilati fisierele p0.sim, p1.sim, p2.sim samd cu compilatorul dvs si rulati-le.
Iata un exemplu, p1.sim:
Aveti in imagine, programul, compilarea si codul generat, rularea.

Iata un exemplu, p2.sim:
Aveti in imagine, programul, compilarea si codul generat, rularea.

Iata un exemplu, p3.sim:
Aveti in imagine, programul, compilarea si codul generat, rularea.
Iata un exemplu, p4.sim:
Aveti in imagine, programul, compilarea si codul generat, rularea.

Bineinteles continua pina la 10.
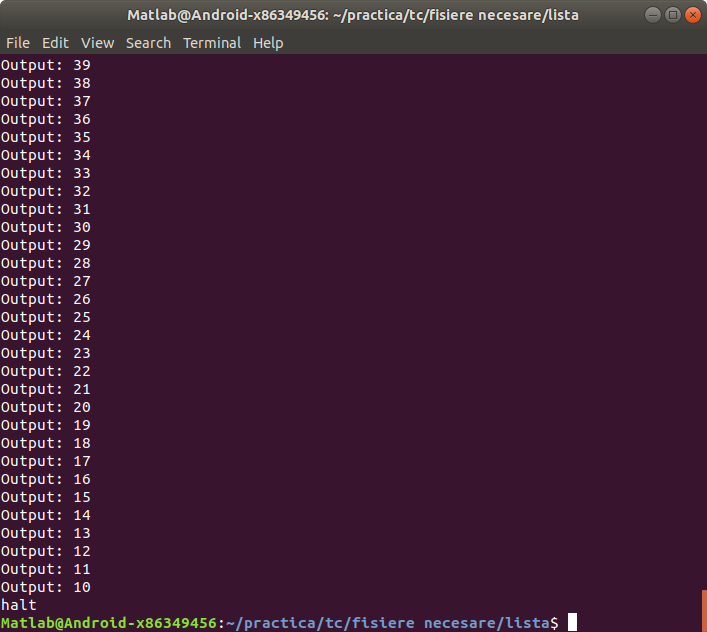
Asa cum scrie in program.
Iata un exemplu, p5.sim:
Aveti in imagine, programul, compilarea si codul generat, rularea.

Sursa programuluyi care calculeaza factorialul.

Codul generat si executia. 4x3x2x1=24, corect, 4!=24
Dupa pauza voi da descrierea portofoliului dvs la LFA - partea de Compilatoare.
Portofoliul dvs la partea de Compilatoare a cursului LFA va contine:
Folderul LAB1 - cu cele 12-19 programe simple, scrise de dvs.
Folderul LAB2 - cu compilatorul realizat exact cat este in Capitolul2
Folderul LAB3 - cu compilatorul realizat exact cat este in Capitolul3
Folderul LAB4 - cu compilatorul realizat exact cat este in Capitolul4
Folderul LAB6 - cu compilatorul realizat exact cat este in Capitolul6
Folderul LAB7 - cu compilatorul realizat exact cat este in Capitolul7
Alte materiale care va vor fi cerute ulterior, pina in sesiune.
Gata pentru azi.
Niciun comentariu:
Trimiteți un comentariu